Planowałem na to 2 godziny…. siedziałem nad tym 5 dni…
 No dobra zacznę od tego że mówimy o zwykłej aktualizacji vCenter Appliance, gdzie można to prawie że przeklikać! przynajmniej wg.”slidów”!
No dobra zacznę od tego że mówimy o zwykłej aktualizacji vCenter Appliance, gdzie można to prawie że przeklikać! przynajmniej wg.”slidów”!
Sytuacja była taka iż klient miał vCenter + ESXi w wersjach 6.5. No to mowie prostszej konfiguracji już nie można mieć. Najpierw oczywiście vCenter. Myślałem sobie ogarnę to nawet w parę godzin. Ehe… takiego wała… oczywiście że tak nie było!
Startowałem od wersji vCenter Appliance (6.5.0.14000 Build Number 7515524) a docelowo przeskakiwałem na tą chwilę najwyższa wersje vCenter Appliance 6.7 U3a ( build 14836122). Miałem do zrobienia zatem tylko jeden… malutki komponent w zasadzie bez żadnych większych zależności. Hosty robiłem później.
Proces jest opisany w dokumentacji i wytłumaczone jest wszystko czarno na białym i powiedzmy że na tym się opierałem. Dodatkowo zgodnie ze swoim zwyczajem przejrzałem środowisko pod kątem wielu czynników na, które powinniśmy się przygotować. Pisałem już trochę w artykule o vCloud Directorze.
Dodatkowo przygotowałem dla Ciebie cały proces w postaci checklisty do pobrania. Chciałbym to mieć jak sam kiedyś zaczynałem.
![]()
Zaczynajmy…
Runda 1
Dla każdego kto aktualizował vCenter wcześniej wie ze proces jest 2 etapowy. Mamy tzw STAGE1 (który w zasadzie składa się tylko z deploymentu nowej maszyny wirtualnej i włączenie jej z tymczasowym adresem IP) oraz STAGE2 gdzie następuje weryfikacja czy żródłowe vCenter spełnia wymagania gotowości do migracji danych na nowy appliance. Dalej już faktyczną migracje danych i uaktywnienie nowego vCentra. To tak w skrócie. Generalnie bułka z masłem! wg. dokumentacji 🙂 i niektórych kolorowych blogów gdzie mamy często zrzuty ekranu z samego klikania i sukcesem na końcu 🙂
Rekomendacja wujka Sebastiana to zrobienie snapshota na nowym vCenter właśnie dopiero jak zakończy się sukcesem STAGE1. Osobiście nie robię snapshota przed STAGE1 bo ma to wpływ na kalkulacje rozmiaru nowego vCentra niestety. Może to powodować po prostu ze kreator wymusi nam większy rozmiar appliance niż rzeczywiście potrzebujemy (i mieliśmy wcześniej). Oczywiście zamiast snapshotu warto mieć backup albo clone zrobiony wcześniej źródłowego vCenter. Snapshot można spokojnie zrobić jak zakończy się STAGE1.
Błąd jaki zobaczyłem podczas procesu weryfikacji STAGE2 będący kluczowym problemem:
“Internal error occurs during VMware vSphere Update Manager pre-upgrade checks.
ResolutionPlease search for these symptoms in the VMware Knowledge Base for any known issues and possible resolutions. If none can be found, collect a support bundle and open a support request.
Error”
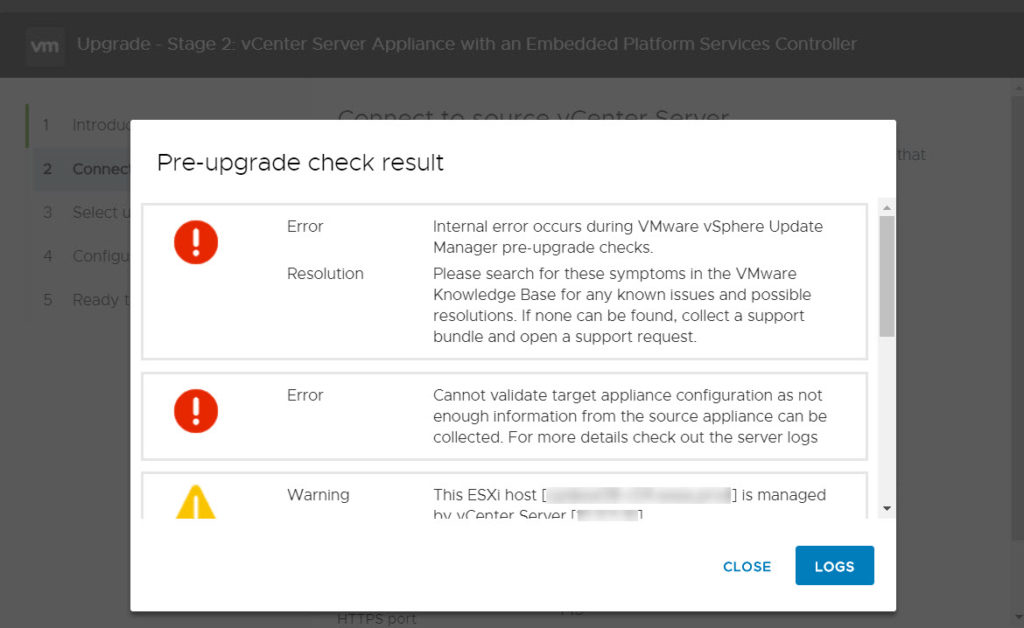
Oznaczało to nic innego jak to że serwis od vSphere Update Managera jest nieosiągalny. W moim przypadku poprostu nie był uruchomiony. Sprawdziłem oczywiście to dopiero po fakcie. A mogłem wcześniej o tym pamiętać. Nie opisze Ci ja włączyć serwis. Nie o tym jest ten wpis. W skrócie można to zrobić w GUI lub łącząc się przez SSH.
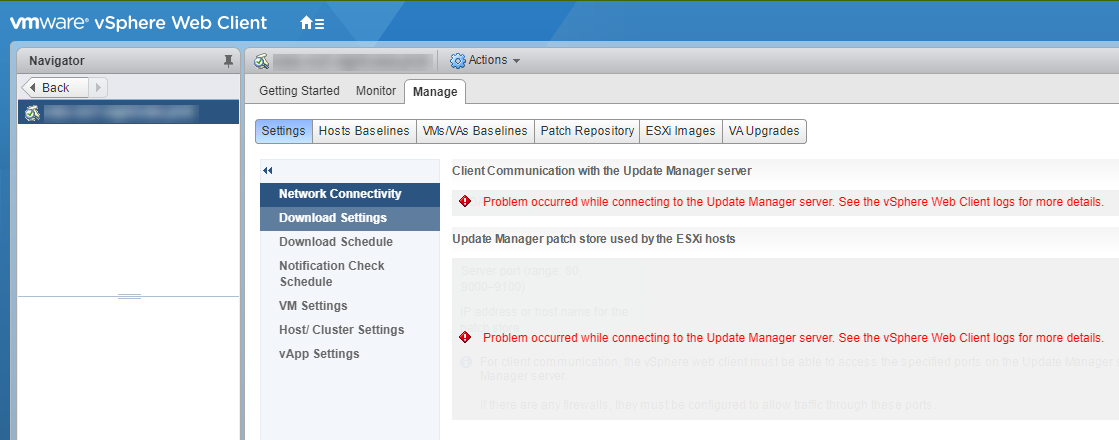
Po włączeniu serwisu ponownie uruchomiłem stronę z konfiguratorem nowego vCentra na etapie początkowej STAGE2 z pełną nadzieją że teraz już w zasadzie z górki 🙂 no dobra nie wierzyłem w to… bo obawiałem się problemu który nie wystąpił tym razem 🙂 Pojawił się jednak inny problem.
Runda 2
Spróbujmy raz jeszcze. Poniższe alerty są czymś normalnym (podczas weryfikacji) i tylko ostrzegają nas o jakimś fakcie. W zasadzie dotychczas miałem chyba z 3 rodzaje ostrzeżeń o które jestem spokojny (do czasu jak nie są to czerwone alerty):
- informacja o tym ze klaster powinien mieć na czas upgrejdu ustawiony DRS na ręczny
- informacja ze jakieś używane przez nas pluginy nie zostaną zmigrowane (u mnie to było VDP i Veeam)
- informacja o tym że dane z vShere Update Manager nie zostaną przegrane (co nie jest problemem)
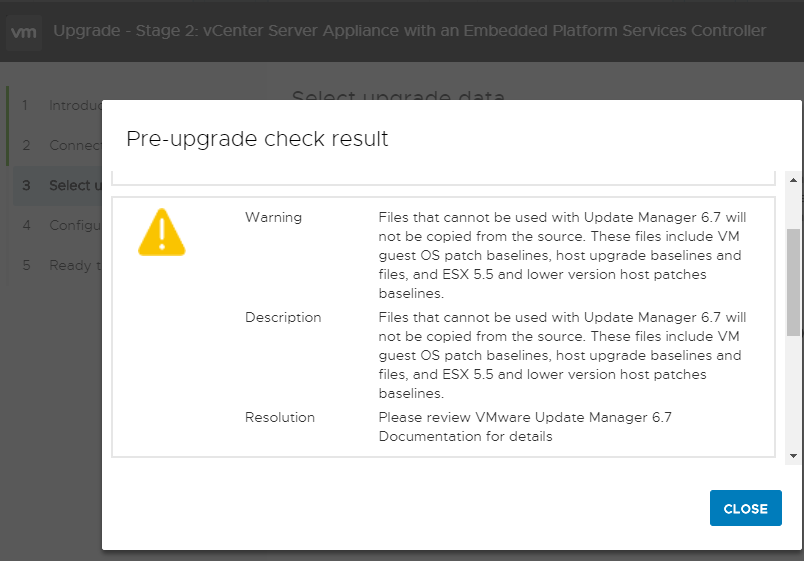
Generalnie powyższe alerty nie dają nam powodów do obaw 🙂 przynajmniej na tym etapie…
Tak mi się wydawało bo zaraz miałem się dowiedzieć że nie taka trawa zielona jak ją malują… czy jakoś tak! 🙂
Idąc dalej to teraz w zależności czy w STAGE2 robimy bezpośrednio po STAGE1 czy też wznawiamy STAGE2 ponownie wpisując dane o które nas kreator poprosi. Kontynuując bierzemy kawę i obserwujemy niczym migrację wielorybów jak zmieniające się taski informują o postępie migracji i kolejno uruchamianych serwisów. Oczywiście pamiętamy że podczas tego procesu źródłowe vCenter zostanie wyłączone i jeśli mamy system monitoringu dobrze go na ten czas przełączyć w tryb uśpienia aby zespól monitorujący jeśli taki posiadamy w swojej organizacji nie dostał zawału jak zobaczy setki alertów w swoim narzędziu. Taki tam przykład:
No dobra pomijając fakt monitoringu widząc pasek postępu na 99% procesu można powiedzieć iż serce rośnie a z dumą zacieramy ręce iż będziemy mogli pokazać nasz profesjonalizm i udowodnić innej części zespołu że robimy takie rzeczy prawie z zamkniętymi oczami… W pewnym momencie naszym oczom ukazuje się…
“Error while configuring vSphere Auto Deploy Waiter firstboot.
Failed to register Auto DeploySearch for these symptoms in the VMware knowledge base for any known issues and possible workarounds. If none can be found, collect a support bundle and open a support request.”
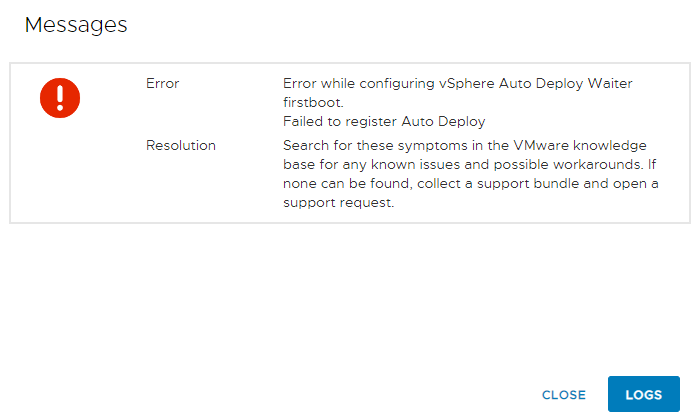
…kawa wypada z ręki a zaczynasz się zastanawiać czy masz backup albo przynajmniej snapshoot…
No dobra ale odrazu nie panikujemy. Klikamy CLOSE i zobaczmy na czym stoimy… w końcu nie używamy “Auto Deploy” i może to tylko jakiś błąd, który niema na nic wpływu. Czasami zastanawiam się skąd u mnie taka naiwność 😀
Początkowo jednak nie było źle…. bo możemy się zalogować do vSphere Clienta. Po chwili jednak zauważyć można że brakuje ikonki oraz sekcji “vSphere Update Managera” i pojawiają się jakieś alerty związane z pluginami, które wcześniej i tak nas ostrzegano ze nie zostaną przeniesione.
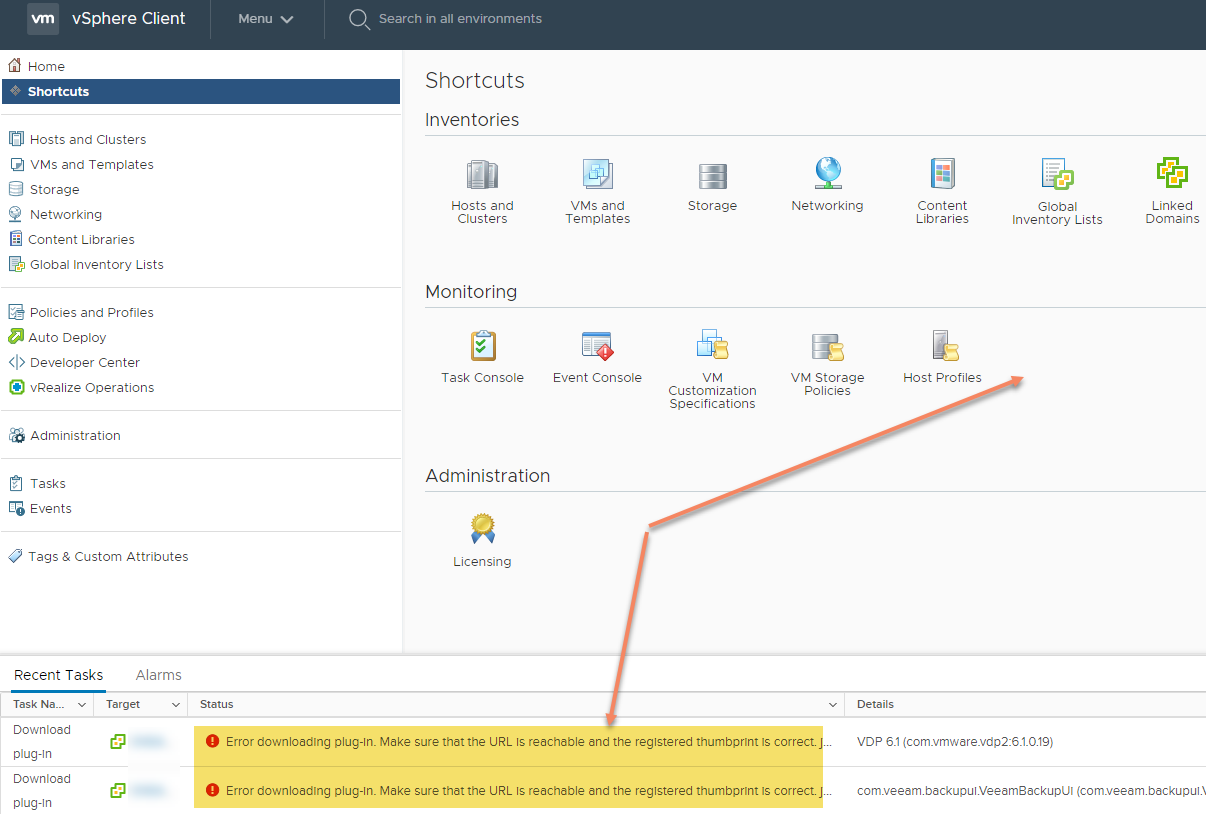
No to na wstępie myśle… zero stresu… usuniemy pluginy poprzez konoslę MOB https://TwojeNowevCenter/mob i może ten plugin to VUMa jakoś magicznie się włączy bo pewnie jest jakiś konflikt. Czas jednak leci i dobrze byłoby otworzyć zatem tą butelkę szampana i zgarnąć należny wynagrodzenie za rozwiązanie problemów klienta. Profilaktycznie zatem sprawdźmy co mówi jeszcze konsola VAMI https://TwojeNowevCenter:5480. I w tym momencie dowiadujemy się jak bardzo w szarej …. jesteśmy.
“This appliance cannot be used or repaired because a failure was encountered. You need to deploy a new appliance”
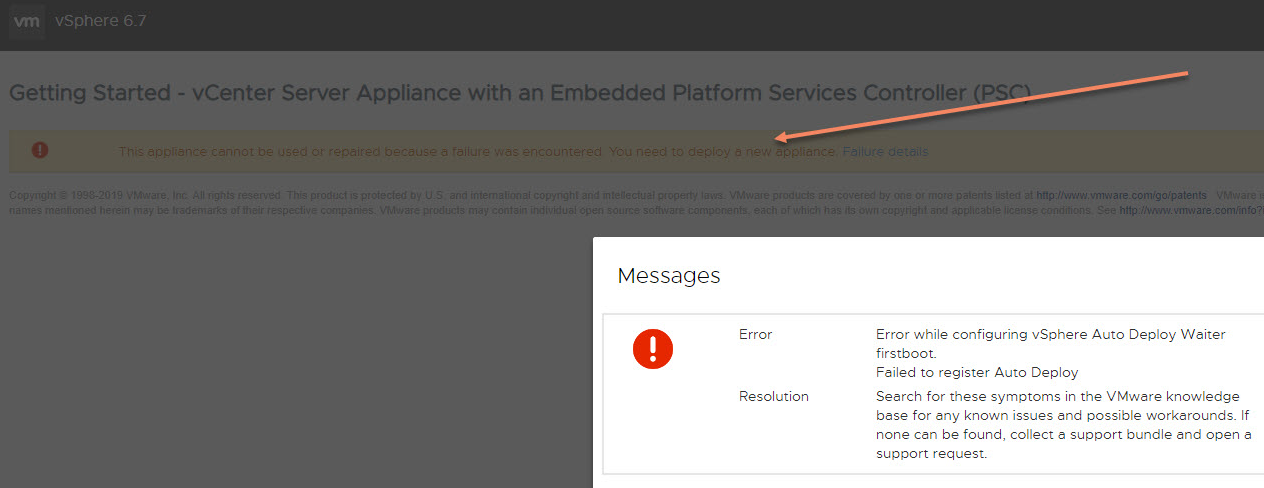
Oczywiście mamy jakieś 40 minut do zakończenia aby zdążyć na wcześniej zaplanowany pociąg…i jak to w IT wszystko trzeba robić w bezpieczny i przemyślany sposób i dodatkowo mieć zaplanowany czas na tzw. roolback 🙂
W tym przypadku nie zostaje nam nic innego (możliwe że są jakieś bardziej wysublimowane sposoby troubleshootingu ale nie dzisiaj) jak sprawdzenie wcześniej przygotowanej listy kroków na powrót do produkcji poprzedniej wersji vCenter. Ponownie zatem ostrzegamy zespół monitorujący o możliwym zwiększeniu aktywności monitoringu na naszym środowisku. Następnie wyłączamy nowe vCenter a włączamy stare. W tym przypadku nie było potrzeby nawet powrotu do snapshota zrobionego po STAGE1 na źródłowym vCenter bo wszystko uruchomiło się bez problemu. Czyli jesteśmy w punkcie wyjścia 🙂 i parę ostatnich godzin poszło w piach…
Runda 3
Chciałbym powiedzieć jak bardzo skuteczne było moje “googlefuu” w poszukiwaniu rozwiązania lub może jeszcze jak bardzo uruchomiłem moje zaułki pamięci i skorzystałem ze swojego doświadczenia ale z uwagi na dość duży impakt na klienta nie chciałem ryzykować i kolejny raz eksperymentować z jego środowiskiem. Otworzyłem sprawę do supportu VMware z pytaniem czy nie mieli już takich zgłoszeń.
Nie byłem oczywiście zaskoczony że jest to dość powszechne i dostałem instrukcje od czego mam zacząć kolejną próbę aktualizacji. Jak to mówią w IT jak nie wiesz czemu coś nie działa to albo to restartujesz albo wyrejestrowujesz i rejestrujesz na nowo 🙂 i takie też dostałem wytyczne z supportu poprzez wykonanie przed samym deploymentem nowego vCentra wykonać komendy:
service-control --stop vmware-rbd-watchdog autodeploy-register -U -a TwojeStarevCenter -p 80 -u Administrator@vsphere.local -m autodeploy-register -R -a TwojeStarevCenter -p 80 -u Administrator@vsphere.local -m service-control --start vmware-rbd-watchdog
Dodatkowo poza wyrejestrowaniem musiałem wyłączyć jeszcze serwis od Auto Deploy na czas tej operacji.
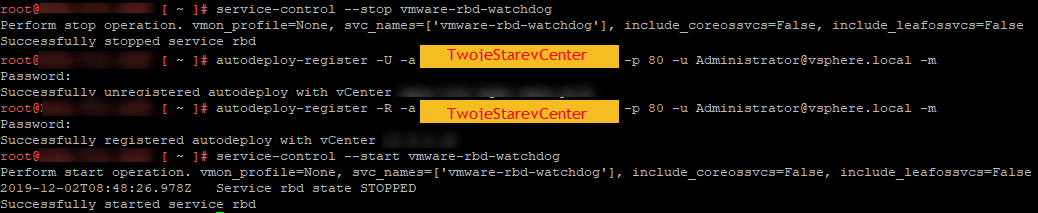
I oczywiście włączyłem ponownie serwis od vSphere Update Manager bo miał jakieś problemy z automatycznym włączeniem.
Nie owijając w bawełnę tym razem proces wyglądał o niebo lepiej i można powiedzieć iż rozpływałem się w samozachwycie. Już tylko czekać jak rozłoży się czerwony dywan a mnie wprowadzą na salony… No dobra ale zejdźmy na ziemię. Czas na analizę tego co się działo i wytknięcie błędów prowodyrowi tego całego zamieszania!
Podsumowanie
Co można by zrobić lepiej ?
- przed startem sprawdzić czy wszystkie serwisy są uruchomione (nie zauważyłem ze serwis od VUMa nie działał)
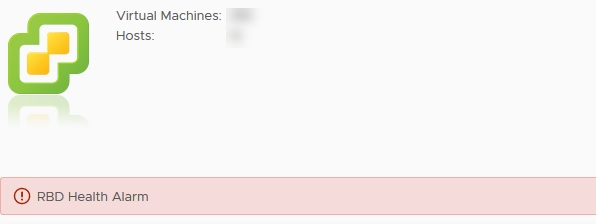
- usunąć (rozwiązać) niezidentyfikowane alerty widoczne na aktualizowanym komponencie. Miałem niezidentyfikowany alert “RBD Health Alarm” i zignorowałem go. Po ponownej analizie prawdopodobnie był związany właśnie z tym Auto Deployem.
Jeśli chciałbyś być na bieżąco i budować swoją wiedzę razem zemną w tematach IT dodaj się do listy mailowej poniżej np. . Co jakiś czas będę podsyłał Tobie informacje co się dzieje na blogu, podcascie “Z Pasją o IT” i w świecie cloud computingu, którym także się zajmuję. Masz jakieś pytania lub myślisz że moglibyśmy zrobić coś razem ? daj znać!
Informacje o nowych artykułach, świecie wirtualizacji i "cloud computingu" prosto na Twojego maila:
Dodam Cię do listy mailowej, z której możesz wypisać się w dowolnym momencie (jeden klik.) | Polityka Prywatności













