Ten artykuł to ósmy z cyklu materiałów, w których szczegółowo przyglądamy się funkcjonalnościom i możliwościom rozwiązania VMware Cloud Director oferowanego przez GigaCloud. Moim celem jest przeanalizowanie poszczególnych komponentów tej platformy oraz pokazanie, jak można je wykorzystać w wybranych aspektach codziennej pracy z chmurą opartej na tej technologii. Każdy artykuł będzie się koncentrował na innym aspekcie VMware Cloud Director – od tworzenia maszyny wirtualnej, testy wydajnościowe, przez backup, migrację aż po awaryjne odtwarzanie (DR).
Zapraszam do śledzenia kolejnych wpisów z tej serii, które będą pojawiać się w najbliższym czasie:
- Przegląd środowiska VMware Cloud Director w Gigacloud.
- Przykładowa konfiguracja środowiska przez GUI (pierwsza maszyna).
- Przykładowa konfiguracja środowiska przez IaC (Terraform i wiele maszyn).
- Testy wydajnościowe łącza internetowego oferowanego przez providera.
- Testy wydajnościowe wdrożonych maszyn dostępnych dysków.
- Weryfikacja i konfiguracja funkcji kopii zapasowych od Veeam udostępnionych na platformie.
- Migracja do VMware Cloud Provider przy pomocy VMware Cloud Director Availability
- Awaryjne odtwarzanie do centrum danych przez VMware Cloud Director Availability.
Wprowadzenie do zakresu bieżącego artykułu
W poprzednich artykułach omówiliśmy ogólny przegląd środowiska VMware Cloud Director oraz proces tworzenia pierwszej maszyny wirtualnej za pomocą interfejsu graficznego (GUI) jak i dalsze wdrożenie na większą skalę poprzez terraform. Przetestowaliśmy łącze internetowe oraz wydajności dysków. Zobaczyliśmy też jak działa usługa do wykonywania kopi zapasowych. Teraz skupimy się na przykładowym scenariuszu awaryjnego odtwarzania grupy maszyn wirtualnych działających jako aplikacja.
Współczesne organizacje coraz silniej opierają swoją działalność na systemach informatycznych, danych i infrastrukturze cyfrowej. W obliczu rosnącej liczby zagrożeń – od awarii technicznych, przez cyberataki, po klęski żywiołowe – kluczowe staje się przygotowanie na sytuacje kryzysowe, które mogą zakłócić ciągłość działania biznesu. Właśnie w tym kontekście pojawia się pojęcie disaster recovery (DR), czyli zestawu procesów, polityk i procedur mających na celu przywrócenie krytycznej infrastruktury IT po wystąpieniu katastrofy, minimalizację przestojów oraz ograniczenie strat danych.
Disaster recovery stanowi nieodłączny element strategii bezpieczeństwa każdej firmy, której zależy na utrzymaniu ciągłości operacyjnej. Brak odpowiedniego planu DR naraża organizację na szereg poważnych konsekwencji, takich jak:
- utrata danych, których nie da się odzyskać,
- długotrwały przestój w działalności i utrata dostępu do kluczowych usług,
- wymierne straty finansowe wynikające z przerw w pracy, kar umownych czy konieczności odtwarzania zasobów od podstaw,
- uszczerbek na wizerunku i spadek zaufania klientów,
- ryzyko niewywiązania się z zobowiązań prawnych i kontraktowych
Statystyki pokazują, że nawet godzina przestoju może generować ogromne koszty – od kilku do kilkuset tysięcy dolarów, w zależności od wielkości przedsiębiorstwa. Dlatego inwestycja w skuteczne rozwiązania disaster recovery nie tylko chroni firmę przed skutkami nieprzewidzianych zdarzeń, ale również zwiększa jej odporność i konkurencyjność na rynku.
Założenia(wymagania) dla konfiguracji:
- RPO < 15 min
- RTO < 4 godz.
Co to oznacza ?
RTO (Recovery Time Objective) definiuje maksymalny akceptowalny czas, w jakim systemy, aplikacje lub usługi muszą zostać przywrócone po awarii, zanim przerwa spowoduje nieakceptowalne straty biznesowe. Jest to kluczowy parametr określający, jak szybko organizacja musi odzyskać operacyjność po incydencie, aby zminimalizować negatywne skutki przestoju.
Ten wskaźnik stanowi fundament skutecznego planu Disaster Recovery, pomagając w:
- Określeniu priorytetów odtwarzania poszczególnych systemów
- Planowaniu niezbędnych zasobów technicznych i ludzkich
- Projektowaniu architektury rozwiązań zapasowych
- Kalkulacji kosztów związanych z wdrożeniem odpowiednich mechanizmów DR
RPO (Recovery Point Objective) określa maksymalną ilość danych, jaką organizacja może zaakceptować do utraty w wyniku awarii lub katastrofy. Ten kluczowy wskaźnik bezpośrednio wpływa na częstotliwość wykonywania kopii zapasowych – im niższy RPO, tym częściej należy tworzyć backupy, aby zminimalizować potencjalną utratę danych.
W praktyce RPO pomaga w:
- Określeniu optymalnej strategii tworzenia kopii zapasowych
- Doborze odpowiednich technologii i narzędzi do ochrony danych
- Kalkulacji kosztów związanych z zabezpieczeniem informacji
- Zrównoważeniu ryzyka utraty danych z kosztami ich ochrony
- Spełnieniu wymogów regulacyjnych dotyczących bezpieczeństwa informacji
Architektura rozwiązania
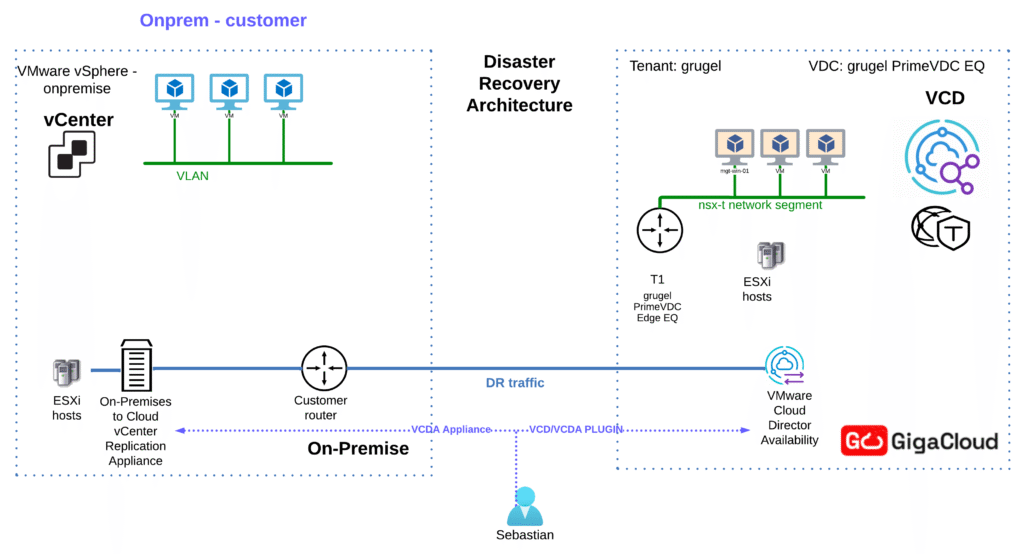
ℹ️ Wdrożenie VMware Cloud Director Appliance opisuje osobno tutaj i w artykule zakładamy że jest już skonfigurowane na potrzeby migracyjne.
Inicjalizacja ochrony(replikacji) maszyn wirtualnych za pomocą VMware Cloud Director Availability do celów odtwarzania awaryjnego.
Przygotuj swoje środowisko:
- Upewnij się, że masz dostęp do VMware vCloud Director i VMware vCloud Director Availability (VCDA) środowisku docelowym z odpowiednimi licancjami do DR (jeśli są wymagane). W tym przypadku VCD od GigaCloud.
- Środowisko vCenter (lokalne), które zabezpieczasz.
Scenariusz:
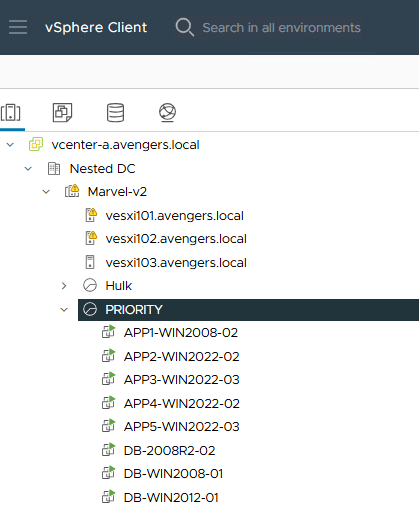
- 5 aplikacji składające się z 8 maszyn
- zabezpieczenie wybranych aplikacji i umiejscowienie ich w tzw.”recovery planach” z podziałem na kroki aby zachować kontrolowaną kolejność odtwarzania zgodnie z wewnętrznymi zależnościami pomiędzy aplikacjami.
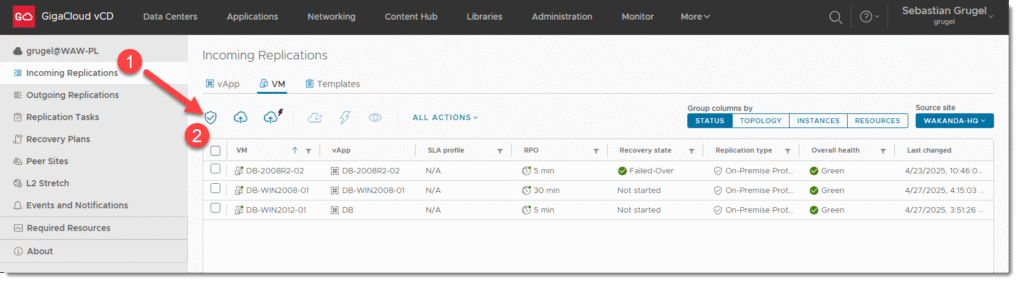
KROK1: Inicjalizowanie ochrony dla określonych maszyn
- Utwórz nową konfiguracje chroniącą maszyny w VCDA w konsoli cloud providera (np. GigaCloud)
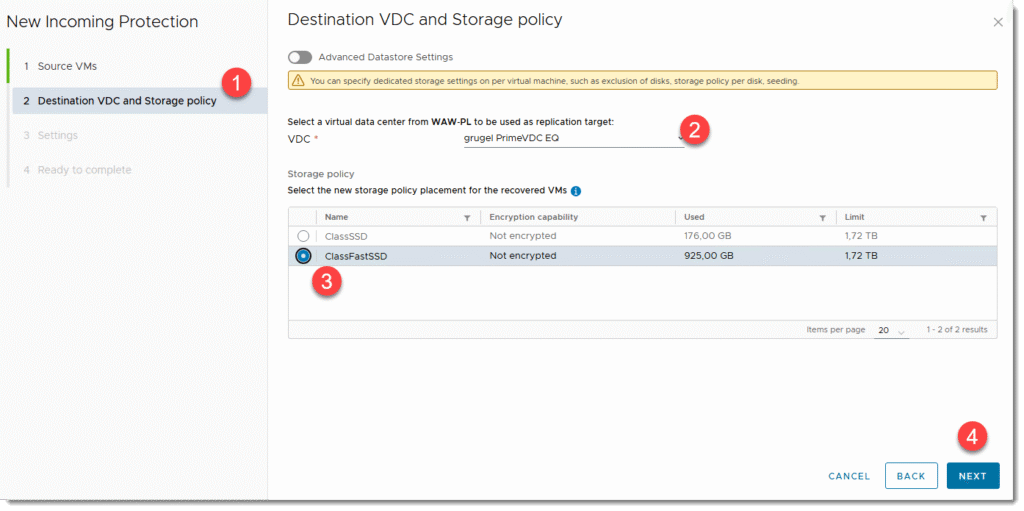
- Wybieramy opcje MORE > AVAILABILITY > INCOMING REPLICATIONS > NEW PROTECTION
- Wybieramy źródłowy endpoint wg zdefiniowanej przez nas nazwy
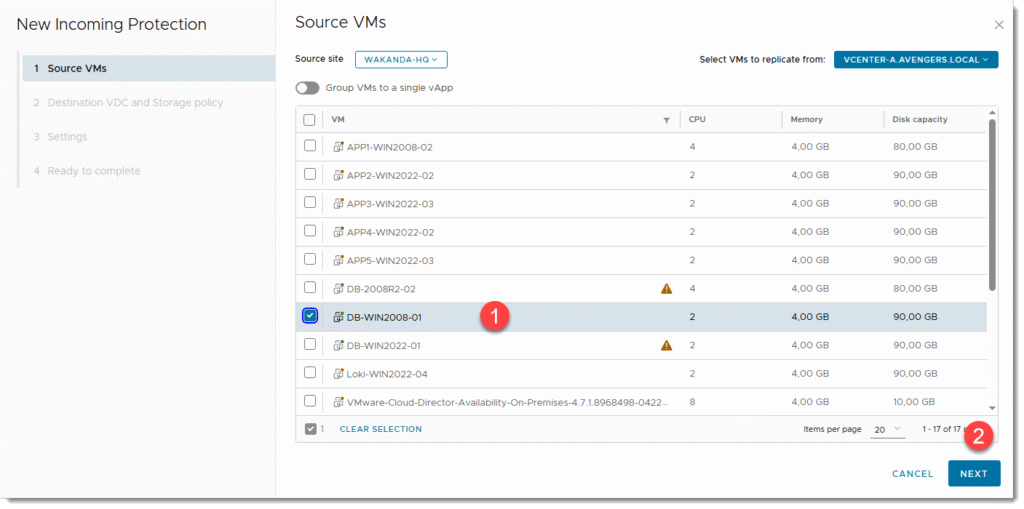
- Następnie zaznaczamy maszyny jakie mamy zamiar migrować i NEXT
- Następnie wybieramy docelowe VDC jeśli mamy więcej niż jedno oraz określamy “storage policy” czyli rodzaj naszej pamięci masowej
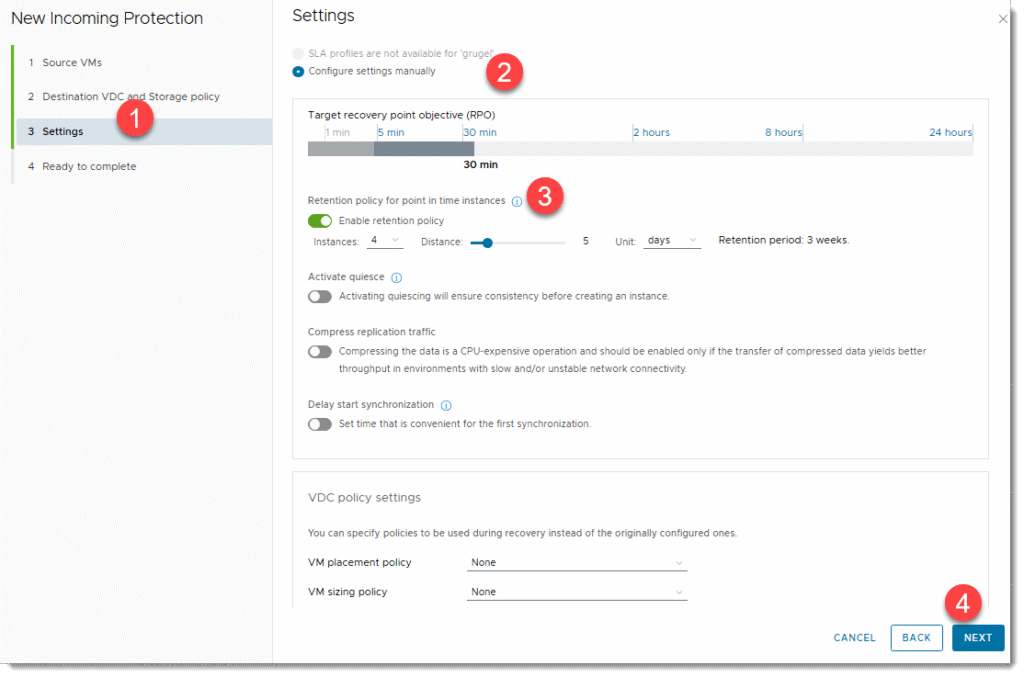
- W zakładce “Settings” możemy zostawić ustawienia domyślne jeśli nic z tego nas nie interesuje.
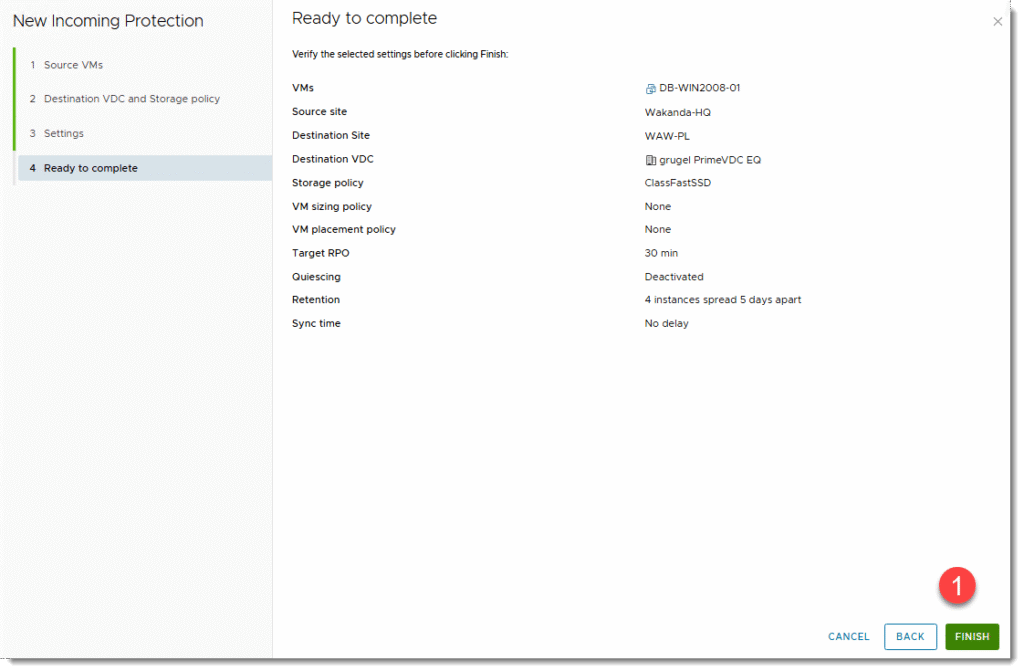
- Na ostatniej stronie weryfikujemy tylko nasze ustawienia i klikamy FINISH
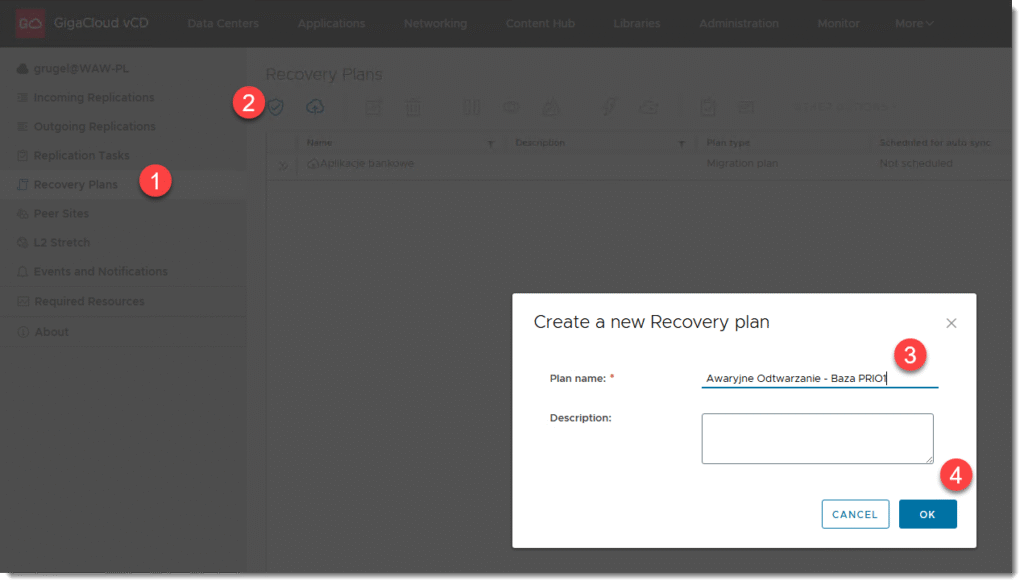
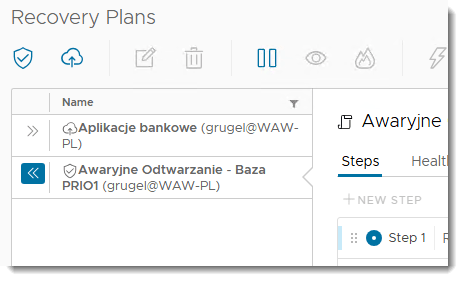
KROK 2: Tworzenie Recovery planów
Jakkolwiek przy samej migracji, recovery plany też można stosować to w przypadku konfiguracji DRu dla naszych aplikacji jest to moim zdaniem niezbędne.
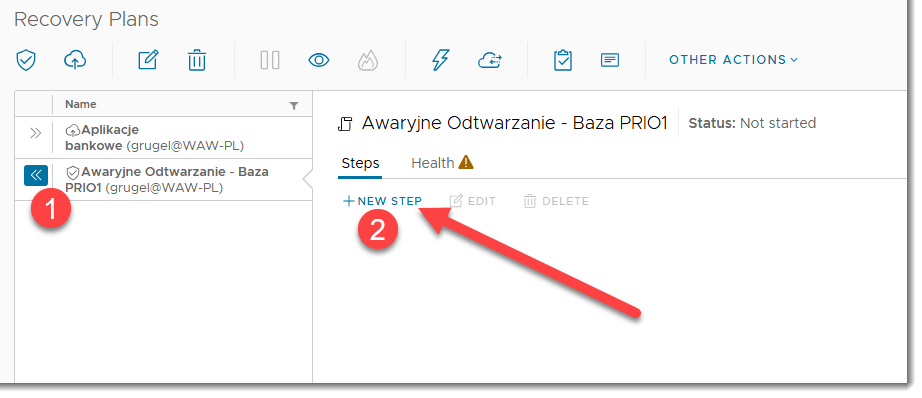
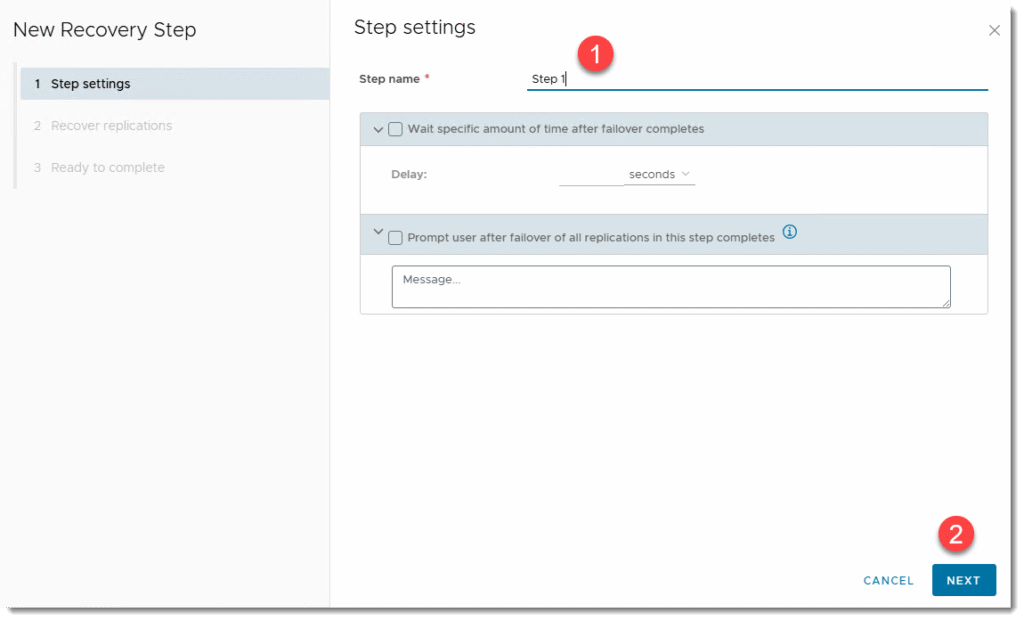
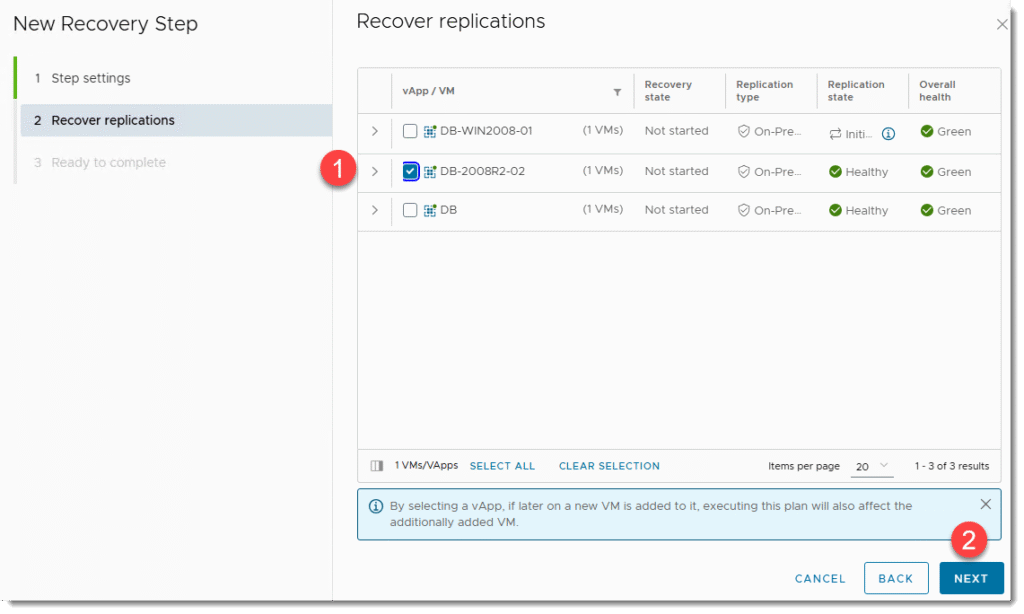
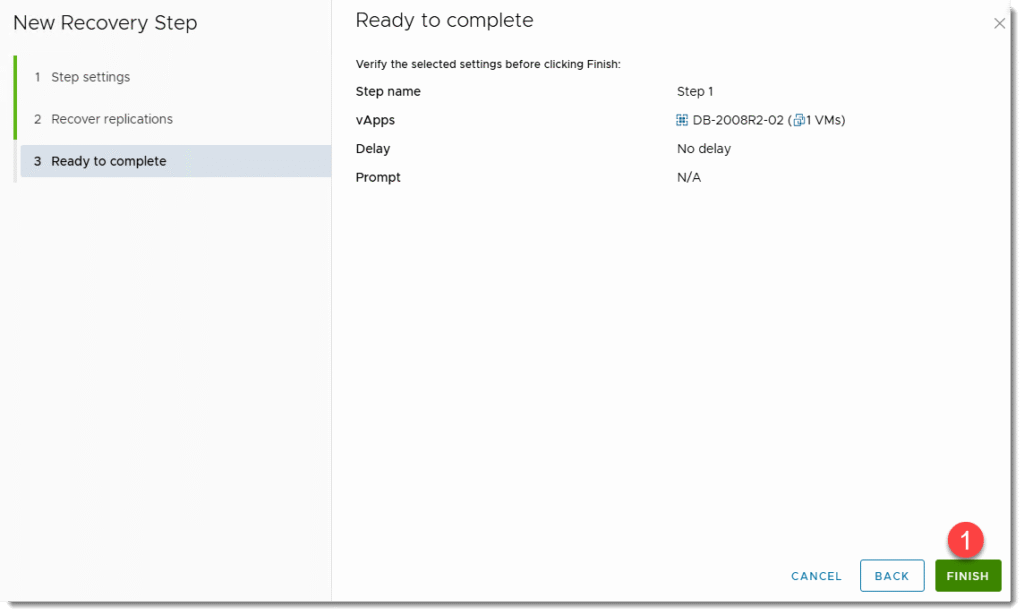
KROK 3a: Testy awaryjnego odtwarzania DR w VMware Cloud Director Availability
Testowanie planu Disaster Recovery w centrach danych jest kluczowe dla zapewnienia realnej skuteczności procedur awaryjnych. Regularne testy pozwalają zweryfikować, czy opracowane procesy rzeczywiście umożliwiają szybkie i poprawne przywrócenie działania infrastruktury IT po awarii, a także ujawniają ewentualne luki lub błędy w dokumentacji i procedurach. Przeprowadzanie testów to nie tylko sprawdzenie technologii, ale również przygotowanie zespołu do działania pod presją – od ich koordynacji i znajomości procedur może zależeć, czy firma przetrwa poważny incydent. Testy umożliwiają także bieżącą aktualizację planu DR oraz szkolenie pracowników, co znacząco zwiększa szanse na skuteczne opanowanie rzeczywistego kryzysu. Brak regularnych testów może sprawić, że nawet najlepiej napisany plan okaże się bezużyteczny w praktyce.
My natomiast w tej części skupimy się na samym narzędziu, które może być częścią większej całości testów testujących ciągłość działania w datacenter. Na poziomie RECOVERY PLAN, zaznaczamy plan, który chcemy przetestować i inicjujemy poprzez przycisk TEST próbne odtworzenie maszyn bez podłączonej sieci. Maszyny zatem są izolowane od realnego środowiska.
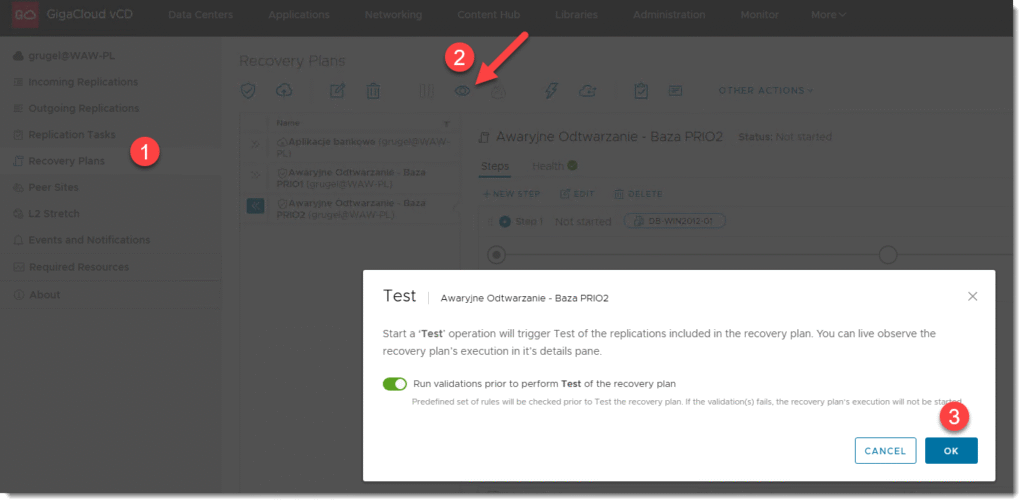
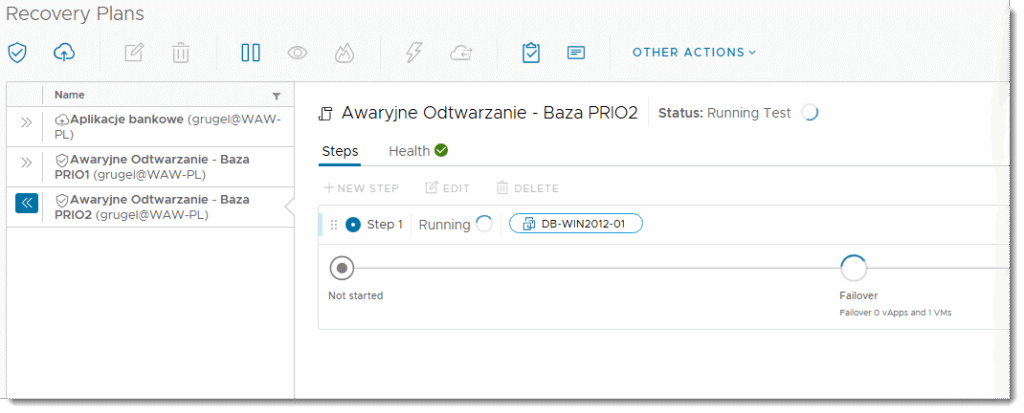
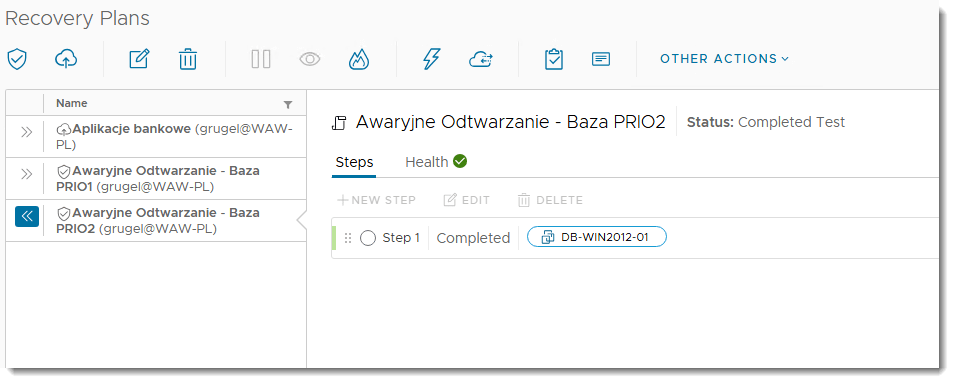
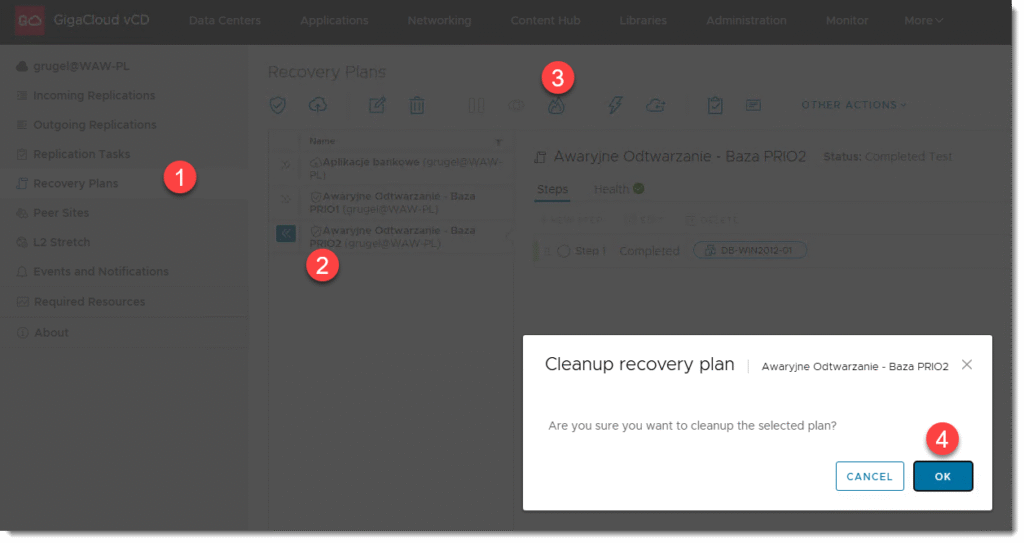
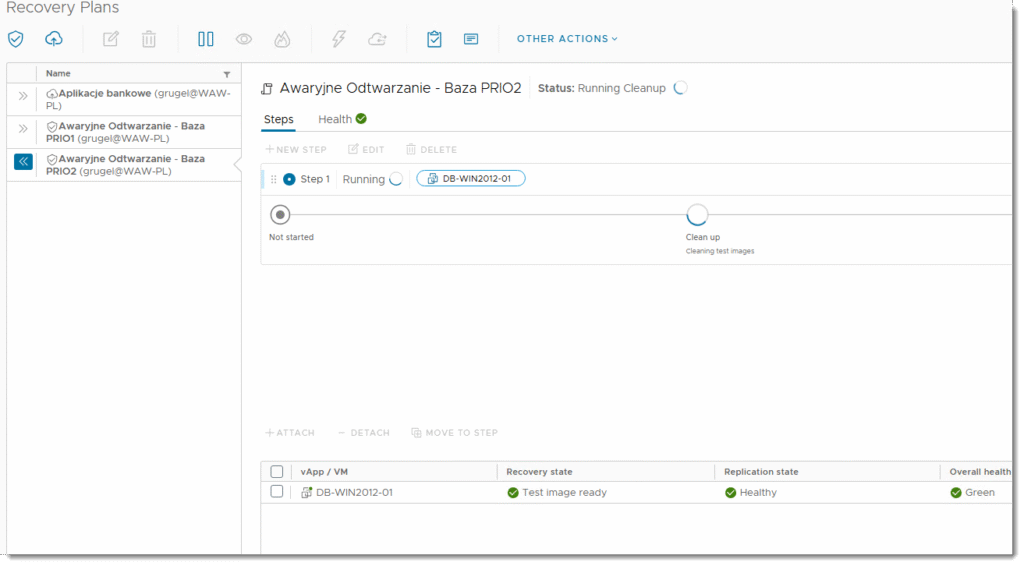
KROK 3b: Raportowanie
VMware Cloud Director Availability oferuje zaawansowane możliwości generowania raportów z testów Disaster Recovery, które są kluczowe dla oceny skuteczności strategii odzyskiwania. Narzędzie dostarcza szczegółowe raporty wykonania planów odzyskiwania (Recovery Plans Execution Reports), zawierające informacje o statusie poszczególnych etapów testu, czasie trwania operacji oraz ewentualnych błędach
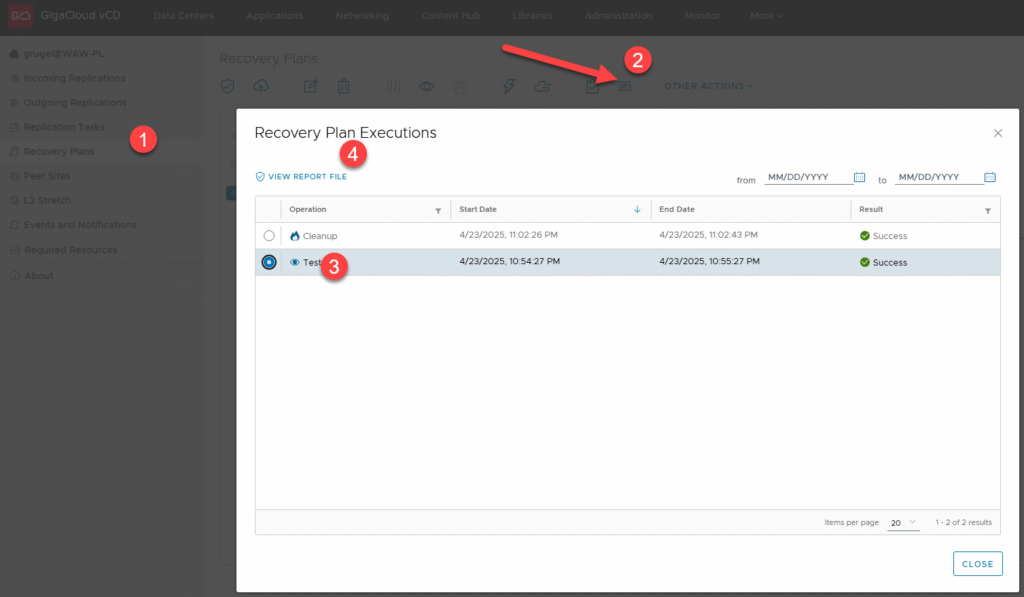
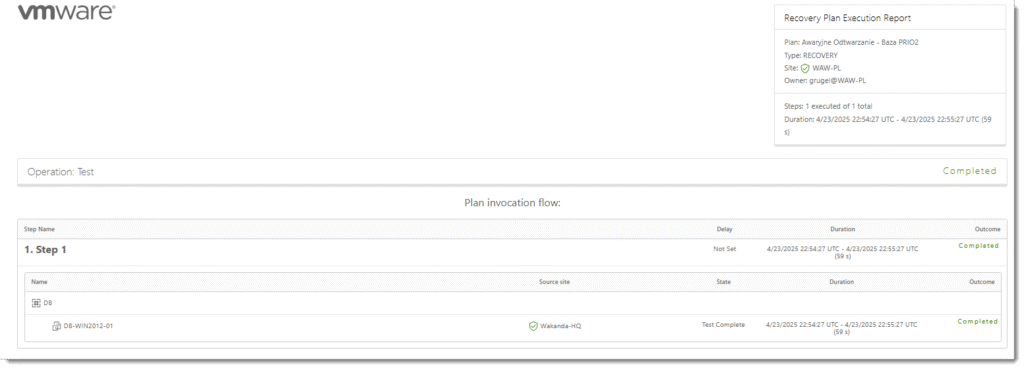
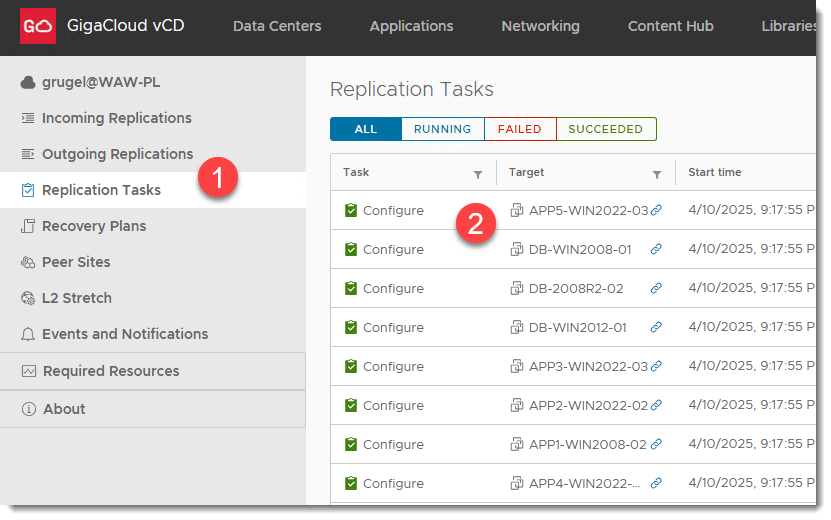
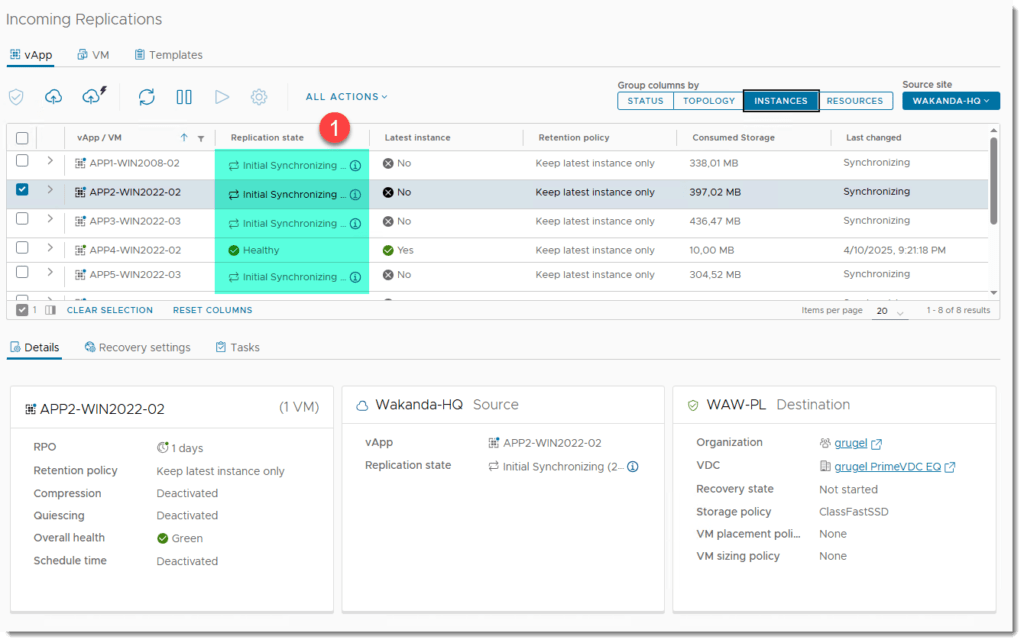
KROK 4: Monitorowanie replikacji
- Weryfikacja poprzez sprawdzenie zadań w “TASKS”
- Weryfikacja czy dane się przesyłają po konsoli VCDA na źródle
- Weryfikacja statusu replikacji w kolumnie “replication state”
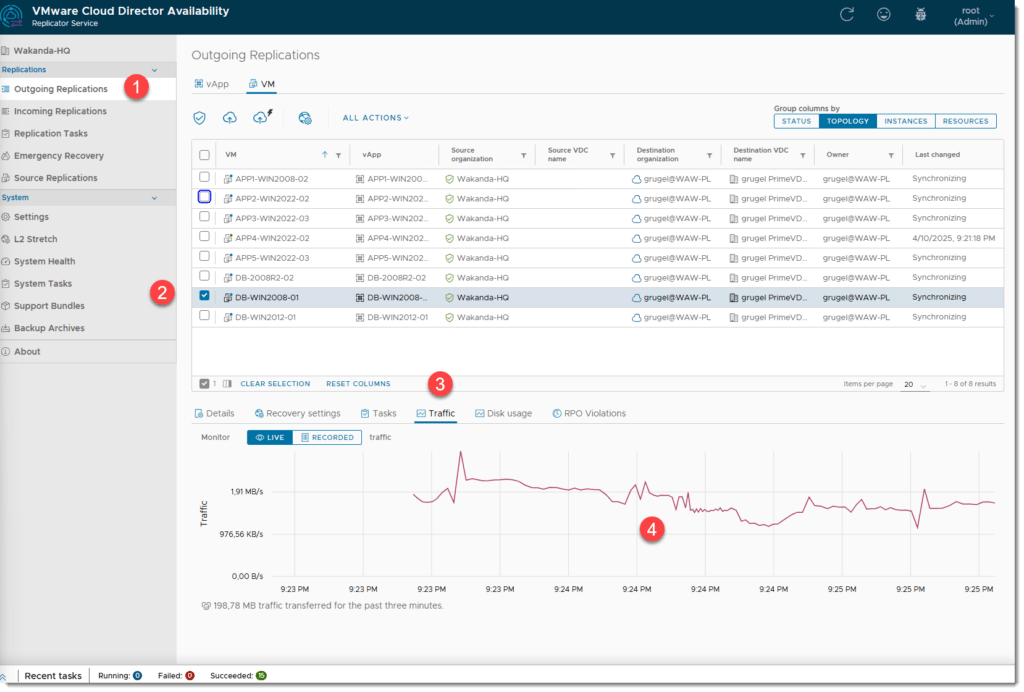
- status replikacji. Zaznaczamy jedną maszynę w OUTGOING REPLICATIONS i po otwarciu się dodatkowej konsoli w dole ekranu klikamy zakładkę TRAFFIC. Obserwować tam możemy o ile następuje właśnie replikacja przesył danych w postaci graficznej. Widać tam też aktualną prędkość przesyłu danej maszyny. Pamiętajmy że przy zrównoleglonych replikacjach prędkość spada na poszczególnej maszynie.
KROK 5: Przełączenie maszyny wirtualnej do docelowego środowiska DR (failover)
- Stworzenie planu odtwarzania (opcjonalnie) tzw. “recovery plans”
- W ramach “recovery plan” możemy podzielić odtwarzanie na kroki (Steps). Przykładowo zgodnie z priorytetem uruchamiania maszyn. Przykładowo najpierw bazy danych, następnie sama aplikacja itd.
- Jeśli mamy wszystko już rozplanowane możemy uruchomić przełączenie awaryjne do docelowego ośrodka zapasowego w przypadku awarii
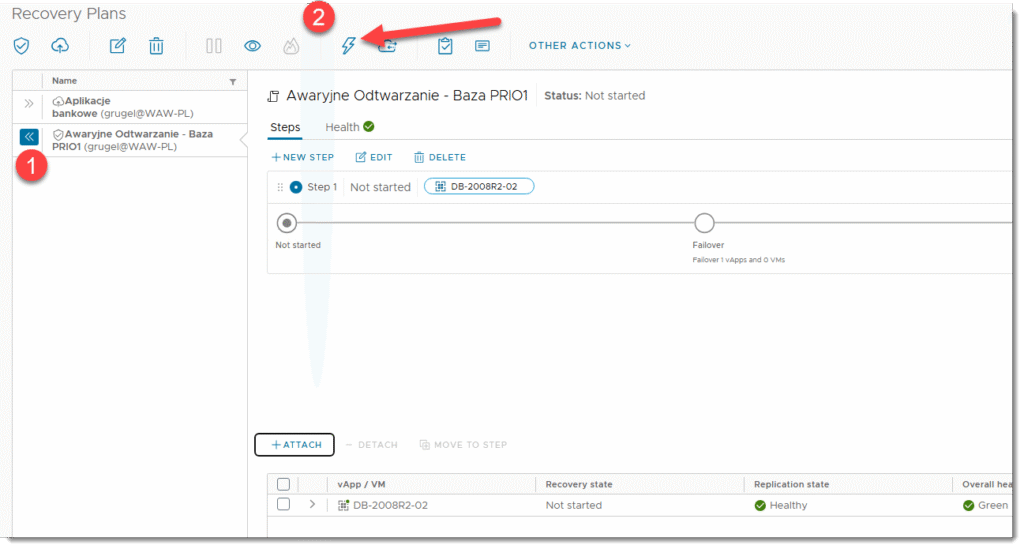
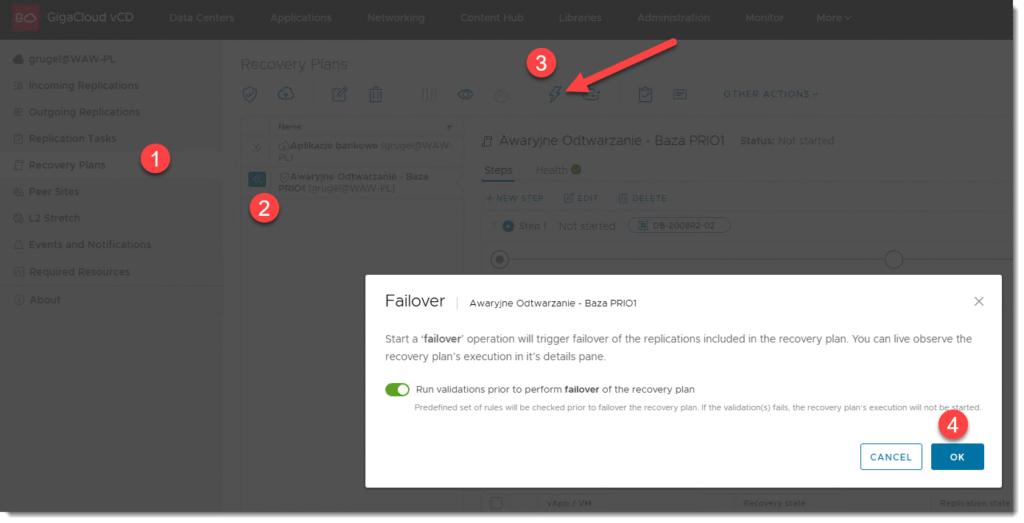
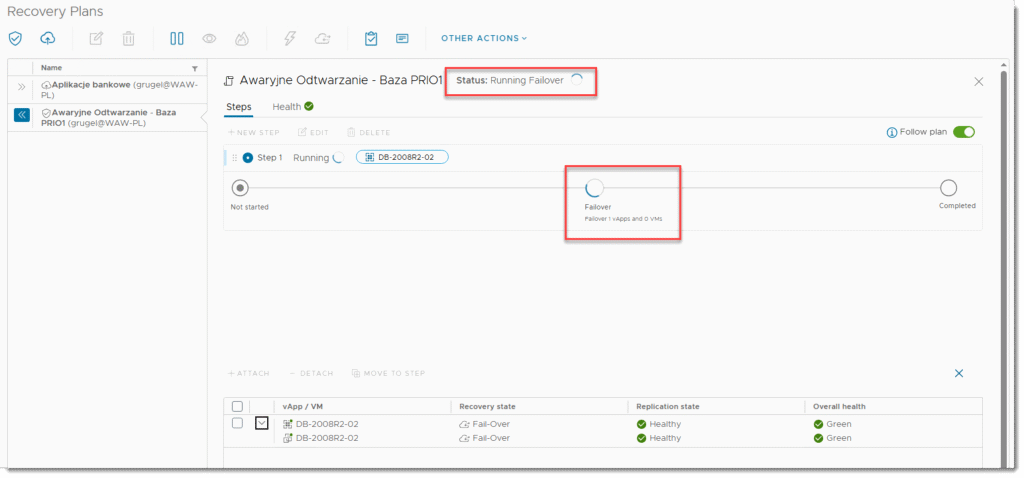
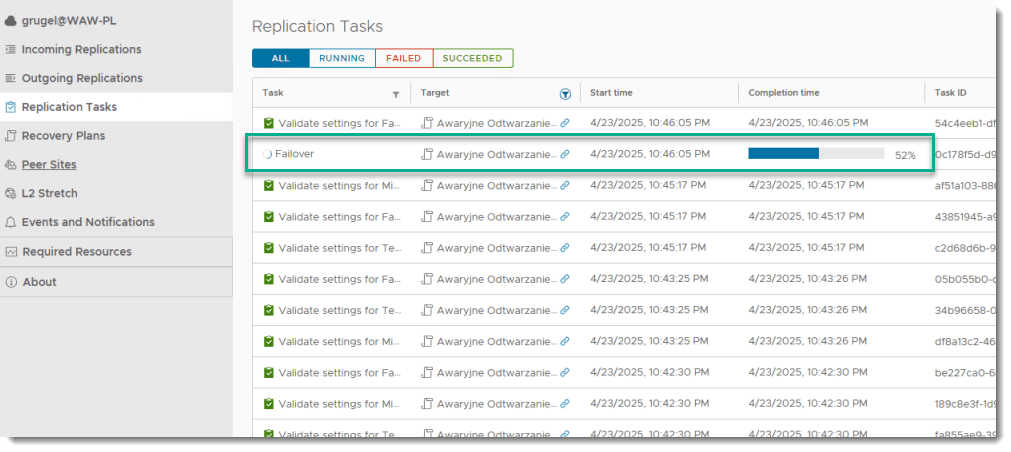
Jak tylko automatyczny proces przełączania się rozpocznie to będziemy świadkiem wyłączania się maszyn na źródle, dosynchronizowywania jeśli będzie taka potrzeba i uruchomienia maszyn w docelowym środowisku. Po tej operacji dalej już tylko kwestia konfiguracji sieciowej wewnątrz naszej organizacji takich jak routing, DNS czy też ustawienia firewalla (zakładam że to przygotowałeś sobie wcześniej) i maszyny powinny ponownie zacząć udostępniać swoje aplikacje z infrastruktury dostawcy chmury. Oczywiście jeśli jest to prawdziwa awaria to maszyny na źródle nie będą zapewne dostępne także nie będzie miało znaczenia czy mechanizm je zacznie wyłączać czy też nie.
Gratuluję! Tak w prostych 3 krokach przeprowadziłeś awaryjne przełączenie DR do nowej platformy chmurowej!
Masz jakieś pytania lub myślisz, że moglibyśmy zrobić wspólny projekt razem ? daj znać!

Informacje o nowych artykułach, świecie wirtualizacji i "cloud computingu" prosto na Twojego maila:
Dodam Cię do listy mailowej, z której możesz wypisać się w dowolnym momencie (jeden klik.) | Polityka Prywatności













